

Which Of The Following Is True About Schemas?
Looking for Confluent Cloud Schema Management docs? These pages cover some aspects of Schema Registry that are generally applicable, such as general concepts, schema formats, hybrid use cases, and tutorials, but the main focus here is Confluent Platform. For Confluent Cloud documentation, check out Manage Schemas on Confluent Cloud.
Schema Registry Overview¶
Confluent Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving your Avro®, JSON Schema, and Protobuf schemas. It stores a versioned history of all schemas based on a specified subject name strategy, provides multiple compatibility settings and allows evolution of schemas according to the configured compatibility settings and expanded support for these schema types. It provides serializers that plug into Apache Kafka® clients that handle schema storage and retrieval for Kafka messages that are sent in any of the supported formats.
Schema Registry lives outside of and separately from your Kafka brokers. Your producers and consumers still talk to Kafka to publish and read data (messages) to topics. Concurrently, they can also talk to Schema Registry to send and retrieve schemas that describe the data models for the messages.
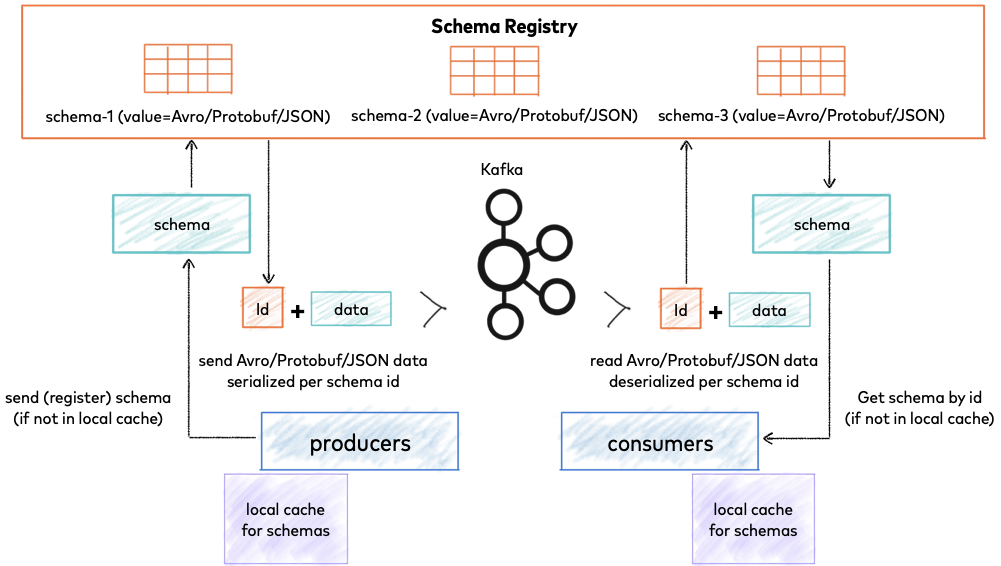
Confluent Schema Registry for storing and retrieving schemas¶
Schema Registry is a distributed storage layer for schemas which uses Kafka as its underlying storage mechanism. Some key design decisions:
- Assigns globally unique ID to each registered schema. Allocated IDs are guaranteed to be monotonically increasing and unique, but not necessarily consecutive.
- Kafka provides the durable backend, and functions as a write-ahead changelog for the state of Schema Registry and the schemas it contains.
- Schema Registry is designed to be distributed, with single-primary architecture, and ZooKeeper/Kafka coordinates primary election (based on the configuration).
See also
To see a working example of Schema Registry, check out Confluent Platform demo. The demo shows you how to deploy a Kafka streaming ETL, including Schema Registry, using ksqlDB for stream processing.
Schemas, Subjects, and Topics¶
First, a quick review of terms and how they fit in the context of Schema Registry: what is a Kafka topic versus a schema versus a subject.
A Kafka topic contains messages, and each message is a key-value pair. Either the message key or the message value, or both, can be serialized as Avro, JSON, or Protobuf. A schema defines the structure of the data format. The Kafka topic name can be independent of the schema name. Schema Registry defines a scope in which schemas can evolve, and that scope is the subject. The name of the subject depends on the configured subject name strategy, which by default is set to derive subject name from topic name.
Starting with Confluent Platform 5.5.0, you can modify the subject name strategy on a per-topic basis. See Change the subject naming strategy for a topic to learn more.
The Schema Registry Tutorials shows an example of a schema definition.
Starting with Confluent Platform 7.0.0, Schema Linking is available in preview, as described in Schema Linking on Confluent Platform (Preview).
Starting with Confluent Platform 5.2.0, you can use Confluent Replicator to migrate schemas from one Schema Registry to another, and automatically rename subjects on the target registry.
Kafka Serializers and Deserializers Background¶
When sending data over the network or storing it in a file, you need a way to encode the data into bytes. The area of data serialization has a long history, but has evolved quite a bit over the last few years. People started with programming language specific serialization such as Java serialization, which makes consuming the data in other languages inconvenient, then moved to language agnostic formats such as pure JSON, but without a strictly defined schema format.
Not having a strictly defined format has two significant drawbacks:
- Data consumers may not understand data producers: The lack of structure makes consuming data in these formats more challenging because fields can be arbitrarily added or removed, and data can even be corrupted. This drawback becomes more severe the more applications or teams across an organization begin consuming a data feed: if an upstream team can make arbitrary changes to the data format at their discretion, then it becomes very difficult to ensure that all downstream consumers will (continue to) be able to interpret the data. What's missing is a "contract" (cf. schema below) for data between the producers and the consumers, similar to the contract of an API.
- Overhead and verbosity: They are verbose because field names and type information have to be explicitly represented in the serialized format, despite the fact that are identical across all messages.
A few cross-language serialization libraries have emerged that require the data structure to be formally defined by schemas. These libraries include Avro, Thrift, Protocol Buffers, and JSON Schema . The advantage of having a schema is that it clearly specifies the structure, the type and the meaning (through documentation) of the data. With a schema, data can also be encoded more efficiently. Avro was the default supported format for Confluent Platform.
For example, an Avro schema defines the data structure in a JSON format. The following Avro schema specifies a user record with two fields: name and favorite_number of type string and int , respectively.
{ "namespace" : "example.avro" , "type" : "record" , "name" : "user" , "fields" : [ { "name" : "name" , "type" : "string" }, { "name" : "favorite_number" , "type" : "int" } ] }
You can then use this Avro schema, for example, to serialize a Java object (POJO) into bytes, and deserialize these bytes back into the Java object.
Avro not only requires a schema during data serialization, but also during data deserialization. Because the schema is provided at decoding time, metadata such as the field names don't have to be explicitly encoded in the data. This makes the binary encoding of Avro data very compact.
Avro, JSON, and Protobuf Supported Formats and Extensibility¶
Avro was the original choice for the default supported schema format in Confluent Platform, with Kafka serializers and deserializers provided for the Avro format.
Confluent Platform supports for Protocol Buffers and JSON Schema along with Avro, the original default format for Confluent Platform. Support for these new serialization formats is not limited to Schema Registry, but provided throughout Confluent Platform. Additionally, Schema Registry is extensible to support adding custom schema formats as schema plugins.
New Kafka serializers and deserializers are available for Protobuf and JSON Schema, along with Avro. The serializers can automatically register schemas when serializing a Protobuf message or a JSON-serializable object. The Protobuf serializer can recursively register all imported schemas, .
The serializers and deserializers are available in multiple languages, including Java, .NET and Python.
Schema Registry supports multiple formats at the same time. For example, you can have Avro schemas in one subject and Protobuf schemas in another. Furthermore, both Protobuf and JSON Schema have their own compatibility rules, so you can have your Protobuf schemas evolve in a backward or forward compatible manner, just as with Avro.
Schema Registry in Confluent Platform also supports for schema references in Protobuf by modeling the import statement.
To learn more, see Formats, Serializers, and Deserializers.
Schema ID Allocation¶
Schema ID allocation always happens in the primary node and Schema IDs are always monotonically increasing.
In Kafka primary election, the Schema ID is always based off the last ID that was written to Kafka store. During a primary re-election, batch allocation happens only after the new primary has caught up with all the records in the store <kafkastore.topic> .
Kafka Backend¶
Kafka is used as Schema Registry storage backend. The special Kafka topic <kafkastore.topic> (default _schemas ), with a single partition, is used as a highly available write ahead log. All schemas, subject/version and ID metadata, and compatibility settings are appended as messages to this log. A Schema Registry instance therefore both produces and consumes messages under the _schemas topic. It produces messages to the log when, for example, new schemas are registered under a subject, or when updates to compatibility settings are registered. Schema Registry consumes from the _schemas log in a background thread, and updates its local caches on consumption of each new _schemas message to reflect the newly added schema or compatibility setting. Updating local state from the Kafka log in this manner ensures durability, ordering, and easy recoverability.
Tip
The Schema Registry topic is compacted and therefore the latest value of every key is retained forever, regardless of the Kafka retention policy. You can validate this with kafka-configs :
kafka-configs --bootstrap-server localhost:9092 --entity-type topics --entity-name _schemas --describe
Your output should resemble:
Configs for topic '_schemas' are cleanup.policy=compact
Single Primary Architecture¶
Schema Registry is designed to work as a distributed service using single primary architecture. In this configuration, at most one Schema Registry instance is the primary at any given moment (ignoring pathological 'zombie primaries'). Only the primary is capable of publishing writes to the underlying Kafka log, but all nodes are capable of directly serving read requests. Secondary nodes serve registration requests indirectly by simply forwarding them to the current primary, and returning the response supplied by the primary. Starting with Confluent Platform 4.0, primary election is accomplished with the Kafka group protocol. (ZooKeeper based primary election was removed in Confluent Platform 7.0.0. )
Note
Please make sure not to mix up the election modes amongst the nodes in same cluster. This will lead to multiple primaries and issues with your operations.
Kafka Coordinator Primary Election¶
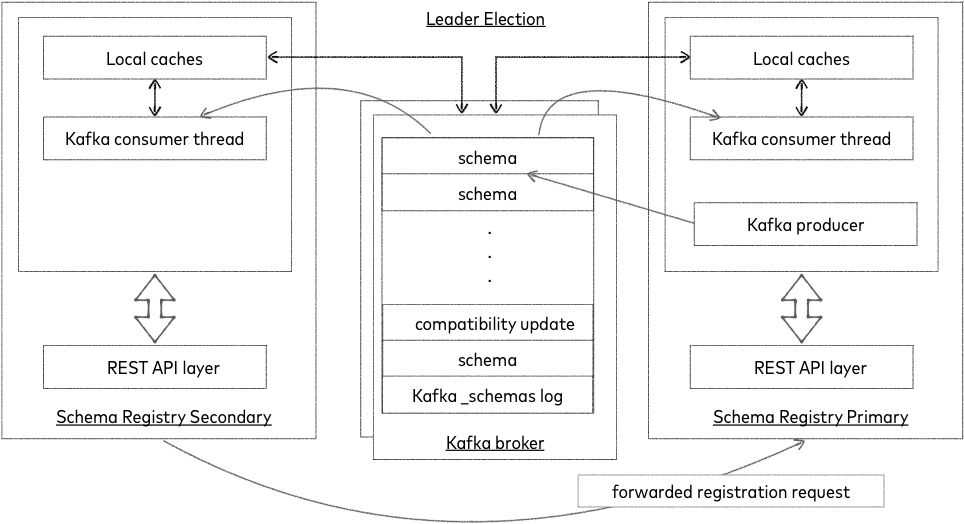
Kafka based Schema Registry¶
Kafka based primary election is chosen when kafkastore.connection.url is not configured and has the Kafka bootstrap brokers <kafkastore.bootstrap.servers> specified. The Kafka group protocol, chooses one amongst the primary eligible nodes leader.eligibility=true as the primary. Kafka based primary election should be used in all cases. (ZooKeeper based leader election was removed in Confluent Platform 7.0.0. See Migration from ZooKeeper primary election to Kafka primary election.)
Schema Registry is also designed for multi-colocated configuration. See Multi-Datacenter Setup for more details.
ZooKeeper Primary Election¶
High Availability for Single Primary Setup¶
Many services in Confluent Platform are effectively stateless (they store state in Kafka and load it on demand at start-up) and can redirect requests automatically. You can treat these services as you would deploying any other stateless application and get high availability features effectively for free by deploying multiple instances. Each instance loads all of the Schema Registry state so any node can serve a READ, and all nodes know how to forward requests to the primary for WRITEs.
A recommended approach is to put the instances behind a single virtual IP or round robin DNS and define multiple URLs for the Schema Registry client in schema.registry.url , thereby using the entire cluster of Schema Registry instances and providing a method for failover.
This also makes it easy to handle changes to the set of servers without having to reconfigure and restart all of your applications. The same strategy applies to REST proxy or Kafka Connect.
A simple setup with just a few nodes means Schema Registry can fail over easily with a simple multi-node deployment and single primary election protocol.
Alternatively, you can use a single URL for schema.registry.url and still use the entire cluster of Schema Registry instances. However, this configuration does not support failover to different Schema Registry instances in a dynamic DNS or virtual IP setup because only one schema.registry.url is surfaced to schema registry clients.
Which Of The Following Is True About Schemas?
Source: https://docs.confluent.io/platform/current/schema-registry/index.html
Posted by: oldhamcopievere.blogspot.com
0 Response to "Which Of The Following Is True About Schemas?"
Post a Comment